Codebox Software
Using a Neural Network to Classify Galaxies
Published:
I've been experimenting with using a neural network to classify images of galaxies, and comparing the results with classifications performed by humans.
Input Data
The source images, downloaded from Galaxy Zoo, are colour JPEG files, 424x424 pixels in size. The quality is sometimes great and sometimes quite poor:
 High Quality Image
High Quality Image
 Low Quality Image
Low Quality Image
The classification that I performed divided the images into 3 groups, describing the overall shape of the galaxy: Spiral, Rounded or Edge-On:
 Spiral Galaxy
Spiral Galaxy
 Round Galaxy
Round Galaxy
 Edge On Galaxy
Edge On Galaxy
Many of the images had similarities to more than 1 of these categories, and the human classifiers had not been able to agree on what type they were. For the initial training of the neural network I used only those images for which at least 90% of the human classifiers had selected the same type - this yielded about 7000 images, roughly equally distributed among the 3 types. I then removed 10% of these images from the training data, and put them aside for use as a validation set. At the end of each training session I would use these validation images to check how the network performed against images on which it had not been trained. This is a common technique used in machine learning to prevent overfitting, where a model works very well with the data you are using to train it, but fails to generalise when it is shown new data.
Data Augmentation
I performed various types of data augmentation on the training images, before showing them to the network:
- Cropping - most of the images have the galaxy in the center, surrounded by quite a lot of black space often containing foreground stars or other objects that were not relevant to the classification process. I cropped all the images around the center, removing about half of each image - this significantly reduced the amount of data that the network had to process, allowing it to train more quickly.
- Shrinking - after cropping, the images were 212x212 pixels in size. I experimented with shrinking the images further by lowering their resolution, and found that at 64x64 pixels most of the relevant features were still clearly visible so I used this smaller size when training.
- Colour Removal - I converted all the images to grayscale before training the network. In general the 3 classes are distinguished by shape rather than colour, and removing colour information from the images reduces their size by two-thirds.
- Random Rotation - each image was rotated by some random amount, between 0° and 360°, each time it was used for training. It was important that the network be able to recognise the different types of galaxy, regardless of their orientation. Performing this rotation greatly increased the variety of training examples shown to the network, and also guarded against any bias that may have been present in the training data that favoured one orientation over another.
- Random Flipping - images were flipped (horizontally and vertically) at random, each time they were shown to the network. Doing this has similar benefits to Random Rotation as described above - it increases the number of unique images that the network sees, and ensures that it learns to disregard this type of transformation when classifying.
Some examples of how the images looked after all the augmentation had been performed are shown below. It is still quite easy to see which class each image belongs to, but now the images contain only about 5% of the data of the originals. Reducing the image size in this way allows the input layer of the neural network to be much smaller, meaning that the network as a whole requires less memory, and will be able to train more quickly.






Network Design
I used Keras running on top of Tensorflow to build the network. I had used Tensorflow before, but not Keras, and I really liked it - it makes a lot of things so much easier!
The network itself comprised 5 hidden layers - 3 convolutional layers, followed by 2 fully-connected layers. I used the RELU activation function after each layer, and a max-pooling layer after each of the convolutional layers. I also used dropout with probability of 0.5 in between the fully-connected layers, as a means to reduce overfitting. So, the overall shape of the network looked like this:
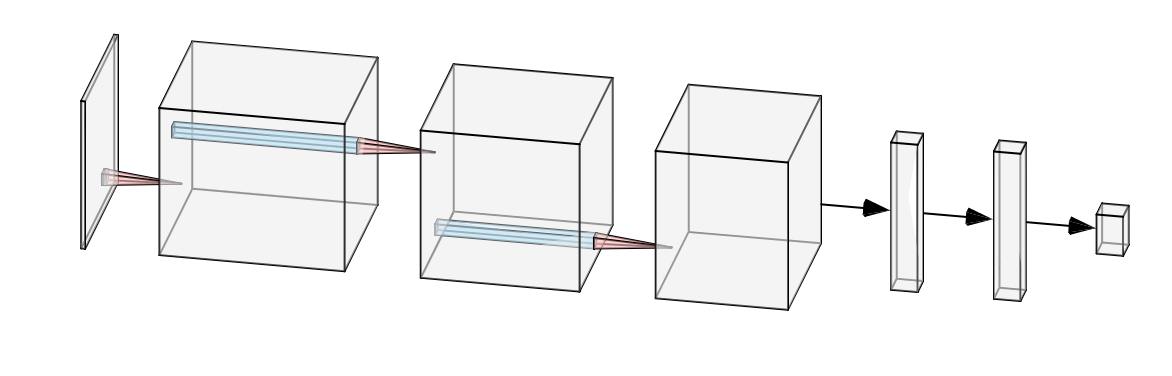
This network is tiny compared to some others, but I needed it to run comfortably on my rather modest laptop.
Results
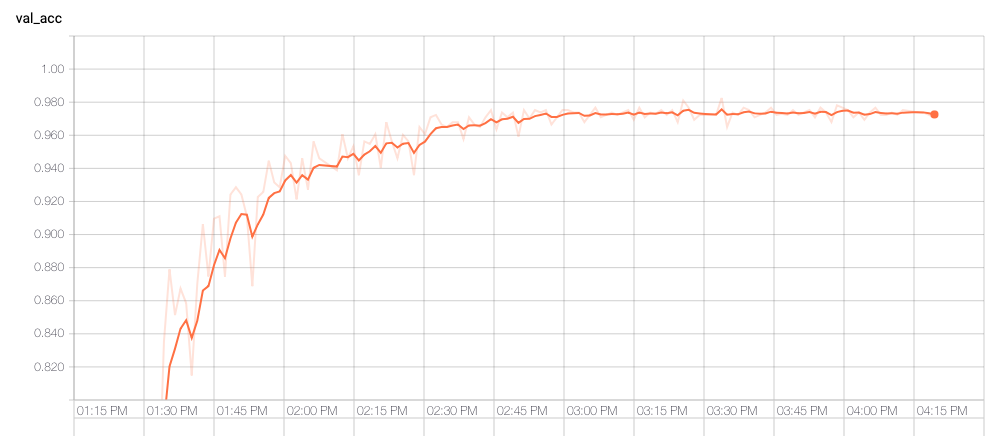
To assess how well the network was performing I monitored the validation accuracy, which is a measure of how closely the network's classifications matched those made by humans, using images that the network had not seen during training. An accuracy of 1 would indicate a perfect correspondence, and 0.33 would indicate predictions no better than chance. The graph below shows that after about an hour the network had achieved accuracy of 0.96. Further training improved the value slightly but it seemed to level off at just over 0.97. I suspect that further training with a smaller learning rate could have pushed that slightly higher, but not by much.
I generated the image below using 30,000 images from the full Galaxy Zoo data set, including those images where there had been disagreement among human classifiers about the correct label. The positioning of each galaxy within the triangle indicates how strongly the neural network thought it resembled each of the 3 classes. Images near the lower vertex are more likely to be spiral, those on the left are more likely to be edge-on, and those on the right to be rounded.

Here are some close-ups of the 3 corners of the image above, showing galaxies with a high probability of belonging to each of the classes:
 Galaxies classified as Spiral
Galaxies classified as Spiral
 Galaxies classified as Round
Galaxies classified as Round
 Galaxies classified as Edge-On
Galaxies classified as Edge-On